
Audio Source Separation w/ Deep Learning
I was curious about source separation tools and stumbled across Spleeter (repo, paper) - a fairly simple architecture for separating audio sources from an input song. I like to learn by building, and the official implementation was written in Tensorflow… so I rewrote it in PyTorch.
Architecture
The goal of the network is to predict the vocal and instrumental components of an input song provided as an audio spectrogram.
Each stem (audio source) is extracted by a separate UNet architecture similar to a convolutional autoencoder using strided convolutions and extra skip-connections.
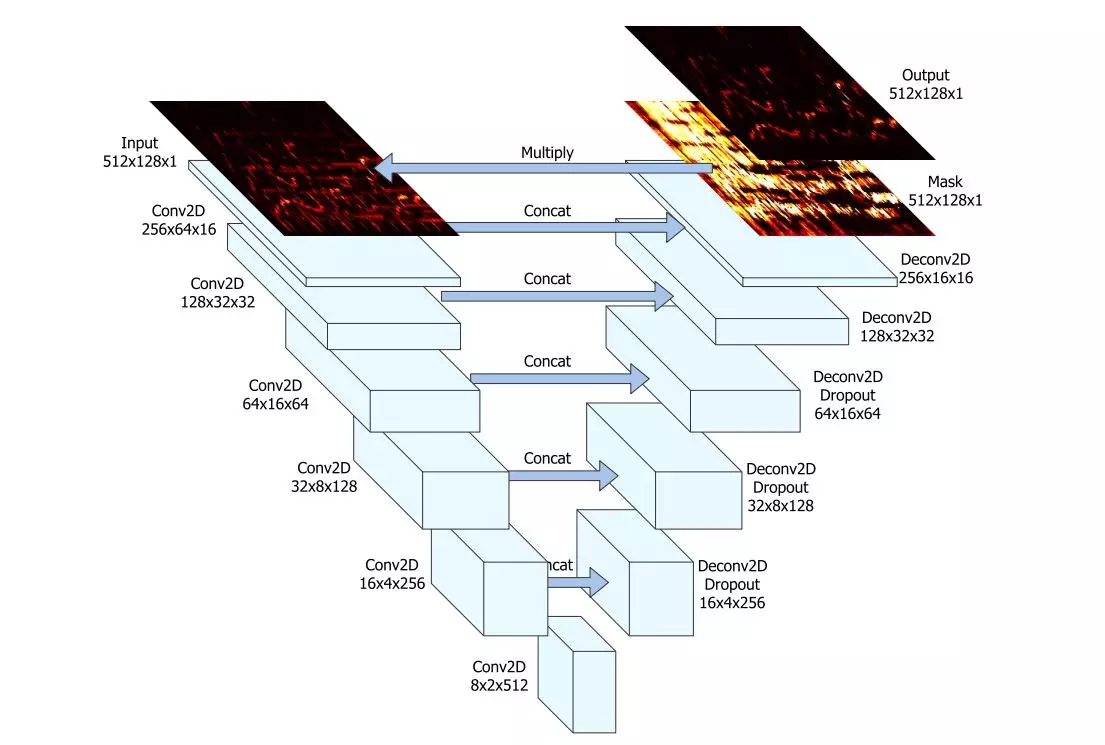
PyTorch Implementation
To create this UNet architecture, I first define the basic blocks required to build our encoding and decoding layers.
Encoding (aka downsampling/compression) is accomplished by passing the source through a set of encoder blocks. In the forward pass, I include the pre-activation convolutional output as we’ll need it later when creating skip connections.
class EncoderBlock(nn.Module):
def __init__(self, in_channels: int, out_channels: int) -> None:
super().__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=5, stride=(2, 2))
self.bn = nn.BatchNorm2d(
num_features=out_channels,
track_running_stats=True,
eps=1e-3,
momentum=0.01,
)
self.relu = nn.LeakyReLU(negative_slope=0.2)
def forward(self, input: Tensor) -> Tuple[Tensor, Tensor]:
down = self.conv(F.pad(input, (1, 2, 1, 2), "constant", 0))
return down, self.relu(self.bn(down))
Decoding (aka upsampling/de-compression) is accomplished by passing the encoded result through a set of decoder blocks. The block looks very similar to the encoder blocks - except we transpose convolution.
class DecoderBlock(nn.Module):
def __init__(
self, in_channels: int, out_channels: int, dropout_prob: float = 0.0
) -> None:
super().__init__()
self.tconv = nn.ConvTranspose2d(
in_channels, out_channels, kernel_size=5, stride=2
)
self.relu = nn.ReLU()
self.bn = nn.BatchNorm2d(
out_channels, track_running_stats=True, eps=1e-3, momentum=0.01
)
self.dropout = nn.Dropout(dropout_prob) if dropout_prob > 0 else nn.Identity()
def forward(self, input: Tensor) -> Tensor:
up = self.tconv(input)
# reverse padding
l, r, t, b = 1, 2, 1, 2
up = up[:, :, l:-r, t:-b]
return self.dropout(self.bn(self.relu(up)))
Putting it all together into a UNet, we have:
class UNet(nn.Module):
def __init__(
self,
n_layers: int = 6,
in_channels: int = 1,
) -> None:
super().__init__()
# DownSample layers
down_set = [in_channels] + [2 ** (i + 4) for i in range(n_layers)]
self.encoder_layers = nn.ModuleList(
[
EncoderBlock(in_channels=in_ch, out_channels=out_ch)
for in_ch, out_ch in zip(down_set[:-1], down_set[1:])
]
)
# UpSample layers
up_set = [1] + [2 ** (i + 4) for i in range(n_layers)]
up_set.reverse()
self.decoder_layers = nn.ModuleList(
[
DecoderBlock(
# doubled for concatenated inputs (skip connections)
in_channels=in_ch if i == 0 else in_ch * 2,
out_channels=out_ch,
# 50 % dropout... first 3 layers only
dropout_prob=0.5 if i < 3 else 0,
)
for i, (in_ch, out_ch) in enumerate(zip(up_set[:-1], up_set[1:]))
]
)
# reconstruct the final mask same as the original channels
self.up_final = nn.Conv2d(1, in_channels, kernel_size=4, dilation=2, padding=3)
self.sigmoid = nn.Sigmoid()
def forward(self, input: Tensor) -> Tensor:
encoder_outputs_pre_act = []
x = input
for down in self.encoder_layers:
conv, x = down(x)
encoder_outputs_pre_act.append(conv)
for i, up in enumerate(self.decoder_layers):
if i == 0:
x = up(encoder_outputs_pre_act.pop())
else:
# merge skip connection
x = up(torch.concat([encoder_outputs_pre_act.pop(), x], axis=1))
mask = self.sigmoid(self.up_final(x))
return mask * input
I added some boilerplate to adapt the pre-trained tensorflow weights to PyTorch and borrowed some code for handling the spectrograms. I’ve uploaded the source here: https://github.com/dcyoung/pt-spleeter
Results
Testing the architecture, it works surprisingly well.
Input - Song (original):
Output - Vocals (predicted):
Output - Accompaniment (predicted):
Comments