
Visualize & Cluster Features using Tensorboard
For the purposes of this example, I’ll create some dummy data:
import numpy as np
# Generate random features and metadata to visualize
sample_embeddings = np.randn(100, 256) # (n_samples, n_features)
sample_metadata = [
{"label": "even" if i % 2 == 0 else "odd"}
for i in range(sample_embeddings.shape[0])
]
Assuming you have the data vectors and meta data you’d like to visualize, you can generate the required files for tensorboard like so:
import tensorflow as tf
from tensorboard.plugins import projector
output_dir = "output"
os.makedirs(output_dir, exist_ok=True)
# Saving the metadata file
def save_meta_tsv(rows: List[Dict[str, Any]], dst: str):
headers = list(meta_by_sample[0].keys())
with open(dst, "w") as f:
f.write("\t".join(headers) + "\n")
for row in rows:
values = [str(row[h]) for h in headers]
f.write("\t".join(values) + "\n")
save_meta_tsv(
rows=sample_metadata,
filepath=os.path.join(output_dir, "metadata.tsv"),
)
# Save the embedding vectors
config = projector.ProjectorConfig()
embedding = config.embeddings.add()
embedding_name = "randomly_generated_test_embedding"
embedding.tensor_name = embedding_name
embedding.metadata_path = os.path.join(output_dir, "metadata.tsv")
projector.visualize_embeddings(output_dir, config)
saver = tf.compat.v1.train.Saver(
[
tf.Variable(sample_embeddings, name=embedding_name)
]
) # Must pass list or dict
saver.save(sess=None, global_step=0, save_path=os.path.join(output_dir, "embedding.ckpt")
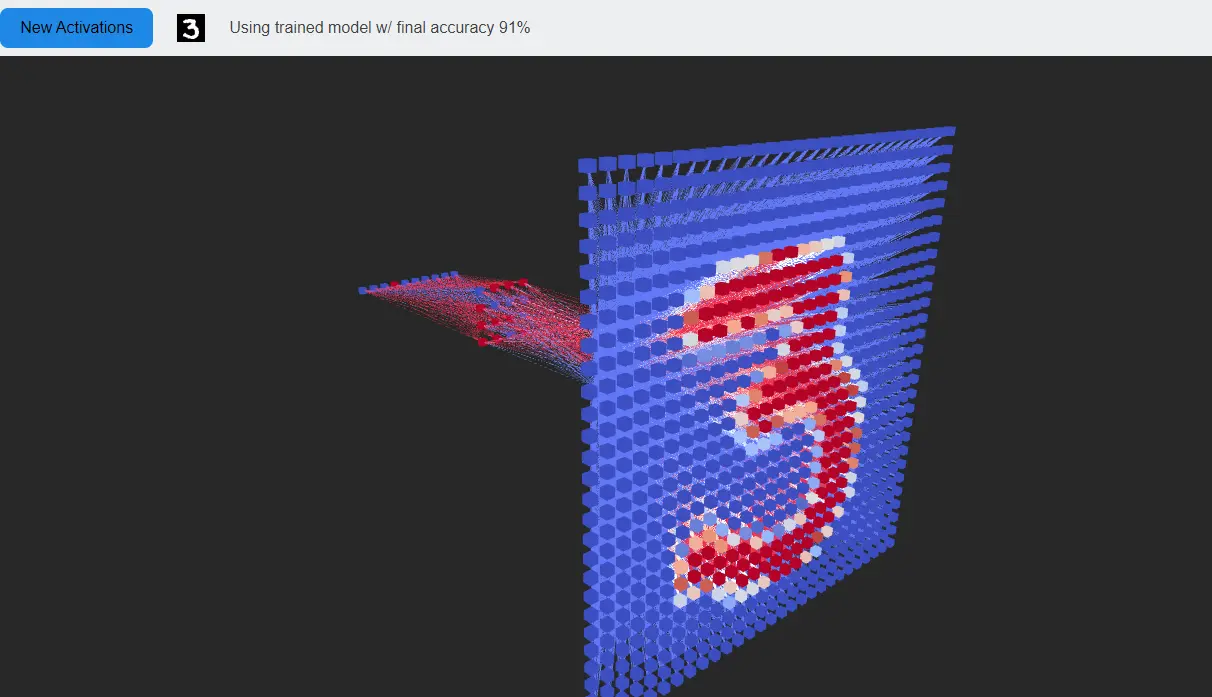
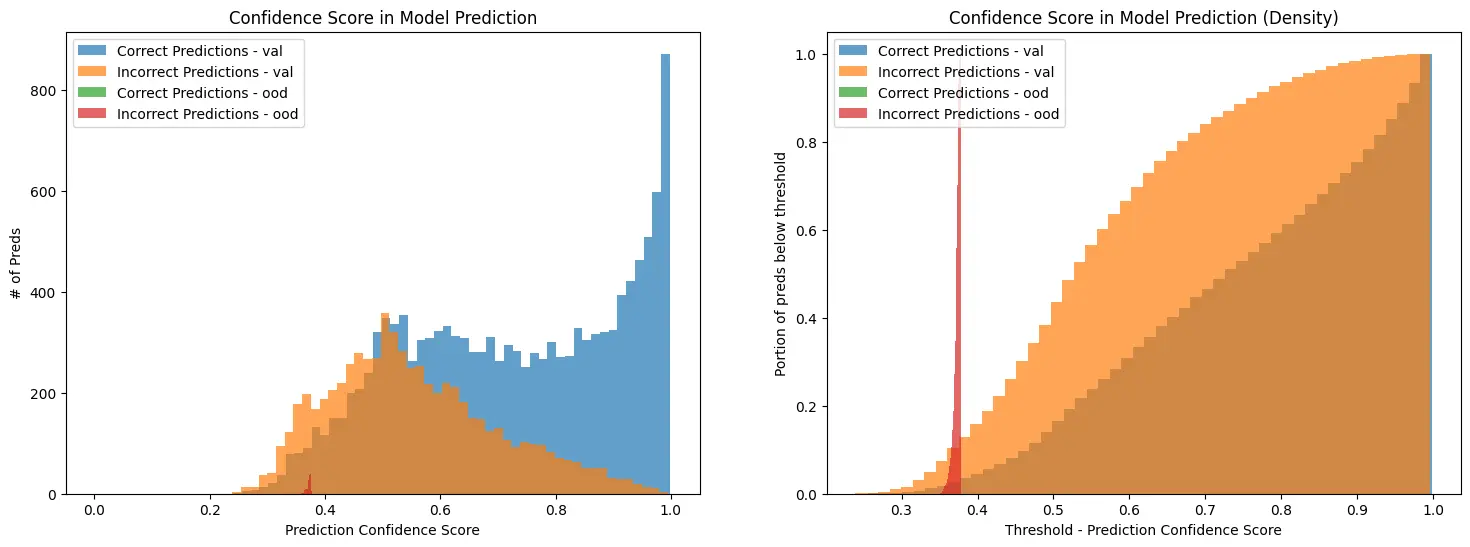
Then, point tensorboard at your output directory and head to the “projector” tab where you can visualize the data with interactive dimensionality reduction techniques such PCA and tSNE.
Comments