
Multi-channel Time Series Classification w/ Deep Learning
Background
I was working on a project to recognize/classify events based on data captured from a small device w/ multiple non-invasive realtime sensors (1D Lidar, PIR, IMU etc). The general category of problem here is multi-channel time series classification, often referenced as Activity Recognition.
For a complete working example see the repository: github.com/detectlabs/detect-CNN-TSC
Data
Gather Labeled Data
I recorded data from the various sensors to yield a continuous timeseries. I then used a custom GUI application to label segments of the timeseries w/ a label corresponding to different events in the time series.
Synchronize Channels
Different sensors collect data at different rates, but most models will operate on dataframes whose values are synchronized. In order to create clean data, the individual channels in the multi-channel time series data must be interpolated at an even sampling rate. This involves reindexing each sample at a desired interval and interpolate new values for each channel.
In pandas, this can be accomplished using interpolate
# Channel readings should be interpolated
for col_name in ["ch0", "ch1", "ch2"...]:
df[col_name] = df[col_name].interpolate("index", limit_direction="both")
# pad any categorical columns (these shouldn't be interpolated)
for col_name in ["label", ...]:
df[col_name] = df[col_name].interpolate("pad")
See here for a complete example.
Format Data
The original dataset is a labeled timeseries. It consists of around 40000 labeled measurements. The sample rate of the original data acquisition was 33ms. Each measurement/data point is 6 dimensional, comprised of 6 unique values (numbers) for each of the synchronized sensor readings. That is to say, each measurement is a row of the timeseries dataset and takes the following form:
<label>, <timestamp_ms>, <ch0>, <ch1>, <ch2>, <ch3>, <ch4>, <ch5>
For example:
LABEL_0, 0, 2134, 2091, -344, -344, -352, -336
LABEL_1, 33, 2164, 2089, -344, -352, -344, -304
LABEL_1, 66, 2103, 2074, -328, -352, -368, -344
...
Segment Samples
Models operate on fixed sized inputs. To train a model, we’ll need to chop up the data. The continuous timeseries is segmented into discrete “samples” each comprised of some fixed quantity of 6-D measurements. Each sample is assigned the label with the highest frequency among the measurements in the sample. Each of these segmented “samples” then serves as a single labeled training data item.
A “sliding window” approach is used to segment the timeseries. For example, consider a window size of 40 and a stride of 2. This means each segmented “sample” is a 40 measurement long window, and these samples are generated every 2 measurements in the original timeseries. To accomplish this, a window spanning 40 measurements will slide through the original timeseries, moving 2 measurements forward each time it generates a new “sample”. Since the stride is so small, these samples overlap quite a bit. 40 measurements at a 33ms interval equates to 1.32 second samples.
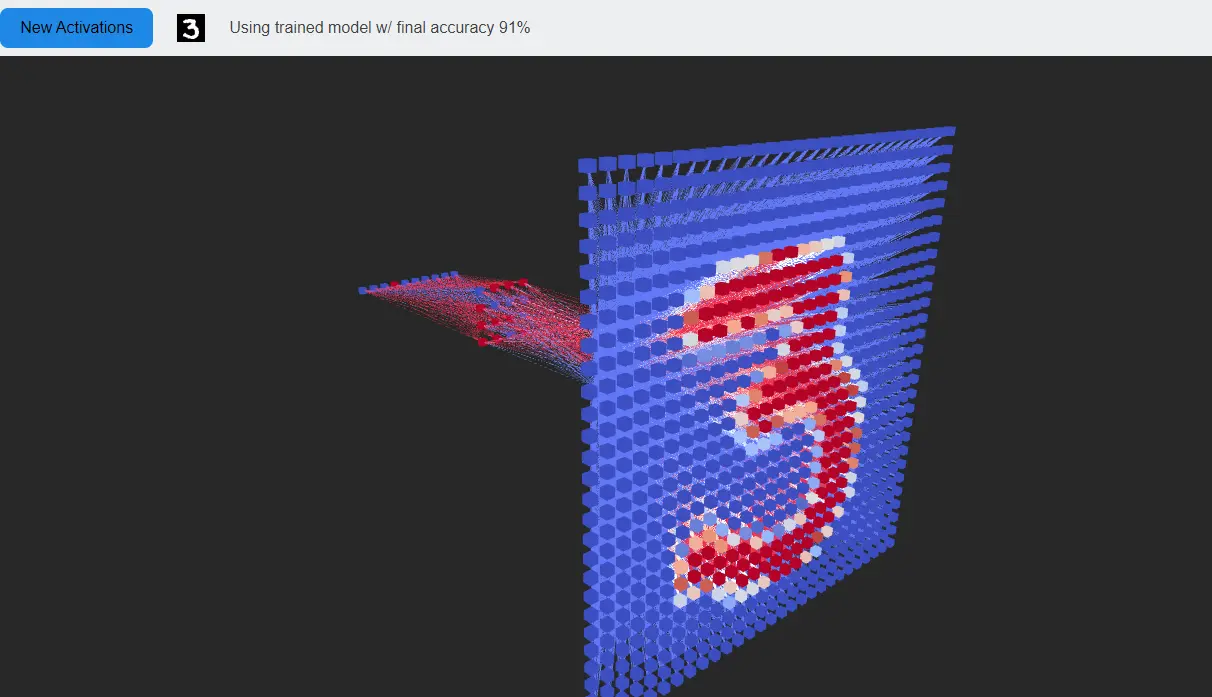
Each sample has size (40, 6) as there are 40 successive measurements, each comprised of 6 dimensions. Think of this like a 2D image.
import numpy as np
from tensorflow.keras.utils import Sequence
from scipy.stats import mode
class TimeseriesGenerator(Sequence):
def __init__(
self,
data,
targets,
length,
sampling_rate=1,
stride=1,
start_index=0,
end_index=None,
shuffle=False,
reverse=False,
batch_size=30,
num_classes=None,
):
if len(data) != len(targets):
raise ValueError(
f"Data and targets have to be of same length. Data length is {len(data)} while target length is {len(targets)}"
)
self.data = data
self.targets = targets
self.length = length
self.sampling_rate = sampling_rate
self.stride = stride
self.start_index = start_index + length
if end_index is None:
end_index = len(data) - 1
self.end_index = end_index
self.shuffle = shuffle
self.reverse = reverse
self.batch_size = batch_size
if num_classes is None:
num_classes = targets.max() + 1
self.num_classes = max(num_classes, targets.max() + 1)
if self.start_index > self.end_index:
raise ValueError(
"`start_index+length=%i > end_index=%i` "
"is disallowed, as no part of the sequence "
"would be left to be used as current step." % (self.start_index, self.end_index)
)
def __len__(self):
return (self.end_index - self.start_index + self.batch_size * self.stride) // (self.batch_size * self.stride)
def _empty_batch(self, num_rows):
samples_shape = [num_rows, self.length // self.sampling_rate]
samples_shape.extend(self.data.shape[1:])
targets_shape = [num_rows, self.length // self.sampling_rate]
return (
np.empty(samples_shape, dtype=np.float32),
np.empty(targets_shape, dtype=np.uint8),
)
def _one_hot_encode(self, labels):
one_hot_encoded = np.zeros((len(labels), self.num_classes), dtype=np.uint8)
one_hot_encoded[np.arange(labels.size), labels] = 1
return one_hot_encoded
def __getitem__(self, index):
if self.shuffle:
row_indices = np.random.randint(self.start_index, self.end_index + 1, size=self.batch_size)
else:
i = self.start_index + self.batch_size * self.stride * index
row_indices = np.arange(i, min(i + self.batch_size * self.stride, self.end_index + 1), self.stride,)
samples, targets = self._empty_batch(len(row_indices))
for j, row_idx in enumerate(row_indices):
sample_indices = range(row_idx - self.length, row_idx, self.sampling_rate)
samples[j] = self.data[sample_indices]
targets[j] = self.targets[sample_indices]
if self.reverse:
return samples[:, ::-1, ...], targets
dominant_class_by_sample = mode(targets, axis=1)[0].flatten()
return samples, self._one_hot_encode(dominant_class_by_sample)
Model
def normalize(data, channel_wise_min, channel_wise_max):
""" Normalizes data to range -1:1, channel-wise. """
cw_range = np.asarray(channel_wise_max) - np.asarray(channel_wise_min)
return (2.0 / cw_range) * (data - channel_wise_min) - 1.0
def build_model(
class_names, input_shape=(30, 6), channel_wise_min=None, channel_wise_max=None, serving_top_k=5,
):
""" Builds a CNN model for Time Series Classification adhering to the provided constraints.
Args:
class_names: the class names (order indicates prediction label)
architecture (str): one of ['fcn', 'cnn', 'resnet', 'inception']
input_shape: Shape of a single input sample [window_size, channels]
channel_wise_min (list<float>): ...
channel_wise_max (list<float>): ...
serving_top_k (int): ...
Returns:
a keras model
"""
num_classes = len(class_names)
model_input = KL.Input(shape=input_shape)
def pre_process(data):
return normalize(data, channel_wise_min, channel_wise_max)
pre_processed_input = KL.Lambda(pre_process)(model_input)
model_output = Resnet_layers(pre_processed_input, num_classes=num_classes)
class ServableModel(tf.keras.Model):
@tf.function(input_signature=[tf.TensorSpec(shape=[None, input_shape[0], input_shape[1]], dtype=tf.float32)])
def serve(self, sequences):
# Make predictions
preds = self.call(sequences)
# Gather top k preds
scores, indices = tf.nn.top_k(preds, min(num_classes, 5))
# Associate class name
class_names_tensor = tf.constant(class_names, dtype=tf.string)
predicted_classes = tf.gather(class_names_tensor, indices)
return {
"classes": predicted_classes,
"scores": scores,
}
def save(
self, filepath, overwrite=True, include_optimizer=True, save_format=None, signatures=None, options=None,
):
if signatures is None:
signatures = {tf.saved_model.DEFAULT_SERVING_SIGNATURE_DEF_KEY: self.serve}
super().save(
filepath=filepath,
overwrite=overwrite,
include_optimizer=include_optimizer,
save_format=save_format,
signatures=signatures,
options=options,
)
model = ServableModel(inputs=model_input, outputs=model_output)
return model
def Resnet_layers(input_tensor, num_classes):
n_feature_maps = 64
# BLOCK 1
conv_x = KL.Conv1D(filters=n_feature_maps, kernel_size=8, padding="same")(input_tensor)
conv_x = KL.BatchNormalization()(conv_x)
conv_x = KL.Activation("relu")(conv_x)
conv_y = KL.Conv1D(filters=n_feature_maps, kernel_size=5, padding="same")(conv_x)
conv_y = KL.BatchNormalization()(conv_y)
conv_y = KL.Activation("relu")(conv_y)
conv_z = KL.Conv1D(filters=n_feature_maps, kernel_size=3, padding="same")(conv_y)
conv_z = KL.BatchNormalization()(conv_z)
# expand channels for the sum
shortcut_y = KL.Conv1D(filters=n_feature_maps, kernel_size=1, padding="same")(input_tensor)
shortcut_y = KL.BatchNormalization()(shortcut_y)
output_block_1 = KL.add([shortcut_y, conv_z])
output_block_1 = KL.Activation("relu")(output_block_1)
# BLOCK 2
conv_x = KL.Conv1D(filters=n_feature_maps * 2, kernel_size=8, padding="same")(output_block_1)
conv_x = KL.BatchNormalization()(conv_x)
conv_x = KL.Activation("relu")(conv_x)
conv_y = KL.Conv1D(filters=n_feature_maps * 2, kernel_size=5, padding="same")(conv_x)
conv_y = KL.BatchNormalization()(conv_y)
conv_y = KL.Activation("relu")(conv_y)
conv_z = KL.Conv1D(filters=n_feature_maps * 2, kernel_size=3, padding="same")(conv_y)
conv_z = KL.BatchNormalization()(conv_z)
# expand channels for the sum
shortcut_y = KL.Conv1D(filters=n_feature_maps * 2, kernel_size=1, padding="same")(output_block_1)
shortcut_y = KL.BatchNormalization()(shortcut_y)
output_block_2 = KL.add([shortcut_y, conv_z])
output_block_2 = KL.Activation("relu")(output_block_2)
# BLOCK 3
conv_x = KL.Conv1D(filters=n_feature_maps * 2, kernel_size=8, padding="same")(output_block_2)
conv_x = KL.BatchNormalization()(conv_x)
conv_x = KL.Activation("relu")(conv_x)
conv_y = KL.Conv1D(filters=n_feature_maps * 2, kernel_size=5, padding="same")(conv_x)
conv_y = KL.BatchNormalization()(conv_y)
conv_y = KL.Activation("relu")(conv_y)
conv_z = KL.Conv1D(filters=n_feature_maps * 2, kernel_size=3, padding="same")(conv_y)
conv_z = KL.BatchNormalization()(conv_z)
# no need to expand channels because they are equal
shortcut_y = KL.BatchNormalization()(output_block_2)
output_block_3 = KL.add([shortcut_y, conv_z])
output_block_3 = KL.Activation("relu")(output_block_3)
# FINAL
gap_layer = KL.GlobalAveragePooling1D()(output_block_3)
return KL.Dense(num_classes, activation="softmax", name="x_train_out")(gap_layer)
Training
# Read csv file
df = pd.read_csv(args.data, skipinitialspace=True)
# Extract class names and convert to integer labels
df[args.label_header] = pd.Categorical(df[args.label_header])
df["LABEL_CODE"] = df[args.label_header].cat.codes
labels = df["LABEL_CODE"].values.astype(np.uint8)
# Package relevant sensor data
data = df[args.channel_headers].values.astype(np.float32)
# Populate class map
CLASS_MAP = {category: i for i, category in enumerate(df[args.label_header].cat.categories)}
# Split the dataset (train/val)
num_train = floor(args.split * len(data))
data_train = data[:num_train]
labels_train = labels[:num_train]
data_val = data[num_train:]
labels_val = labels[num_train:]
# Create a data generator
training_data_gen = TimeseriesGenerator(
data=data_train,
targets=labels_train,
length=SAMPLE_LENGTH,
sampling_rate=SAMPLING_RATE,
stride=STRIDE,
start_index=0,
end_index=None,
shuffle=True,
reverse=False,
batch_size=BATCH_SIZE,
num_classes=len(CLASS_MAP),
)
...
# Build the model
model = build_model(
class_names=list(CLASS_MAP.keys()),
input_shape=(SAMPLE_LENGTH, data.shape[-1]),
channel_wise_min=[float(x) for x in np.min(data_train, axis=0)],
channel_wise_max=[float(x) for x in np.max(data_train, axis=0)],
)
model.compile(
optimizer=Adam(lr=LEARNING_RATE),
loss="categorical_crossentropy",
metrics=[
"accuracy",
CategoricalAccuracy(),
AUC(),
Precision(),
Recall(),
TopKCategoricalAccuracy(k=2, name="top_k_2_categorical_accuracy"),
TopKCategoricalAccuracy(k=5, name="top_k_5_categorical_accuracy"),
TrueNegatives(),
TruePositives(),
FalseNegatives(),
FalsePositives(),
],
)
steps_per_epoch = len(training_data_gen) if STEPS_PER_EPOCH is None else STEPS_PER_EPOCH
validation_steps = len(validation_data_gen) if VALIDATION_STEPS is None else VALIDATION_STEPS
model.fit_generator(
generator=training_data_gen,
steps_per_epoch=steps_per_epoch,
epochs=NUM_EPOCHS,
use_multiprocessing=False,
validation_data=validation_data_gen,
validation_steps=validation_steps,
verbose=1,
callbacks=[
ReduceLROnPlateau(
# monitor="loss",
monitor="val_accuracy",
factor=0.5,
patience=8,
min_lr=LEARNING_RATE / 10,
),
TensorBoard(log_dir=log_dir, histogram_freq=0, write_graph=False, write_images=False),
ModelCheckpoint(filepath=checkpoint_prefix, monitor="val_loss", save_best_only=True),
],
)
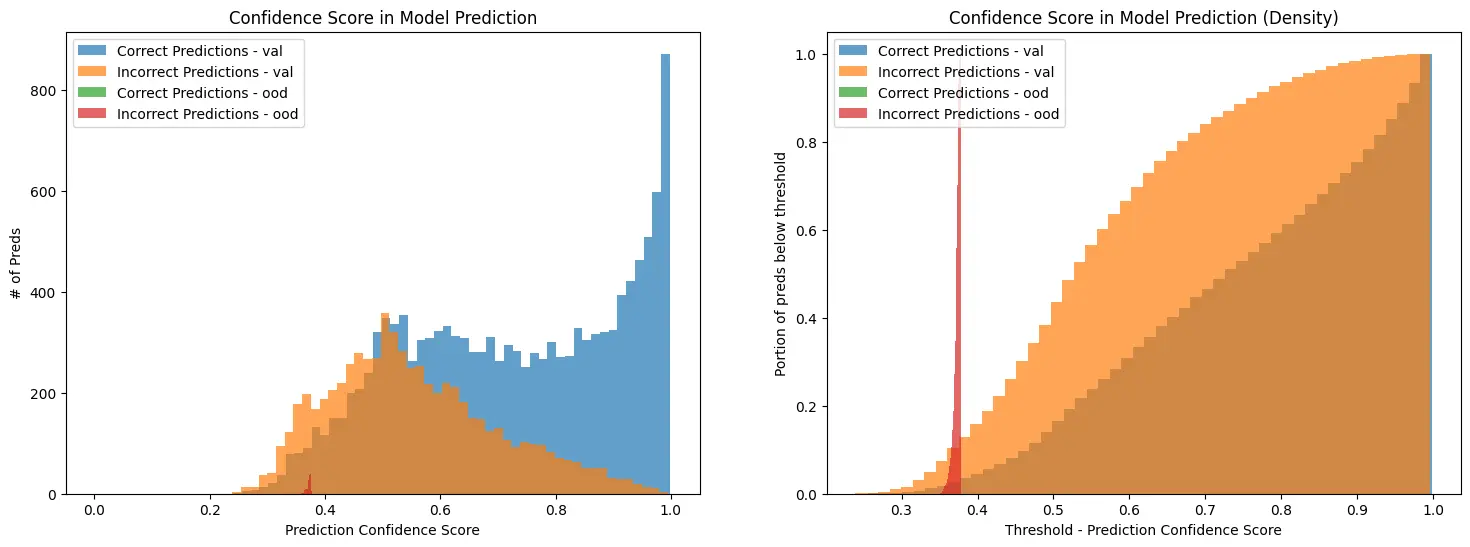
Serving Predictions w/ TFServing
While training, the model saves off checkpoints with proper serving checkpoints. Once training is complete, you can use docker to serve predictions to remote clients.
# Download the tensorflow serving docker image
docker pull tensorflow/serving
# Location of exported servable
CKPT_DIR=<path_to_training_ckpt_dir>
# Desired name for the served model
MODEL_NAME=classifier
# Start TensorFlow Serving container
docker run -it \
--rm \
-p 8500:8500 \ # GRPC endpoint
-p 8501:8501 \ # REST endpoint
-v $CKPT_DIR:/models/$MODEL_NAME/1 \
-e MODEL_NAME=$MODEL_NAME \
tensorflow/serving
# Test endpoint
curl http://localhost:8501/v1/models/$MODEL_NAME
Once the model server is running, predictions can be querried like so:
def build_request(sample_batch, model_name="classifier"):
request = predict_pb2.PredictRequest()
tp_data = make_tensor_proto(sample_batch, dtype=tf.float32)
request.model_spec.name = model_name
request.model_spec.signature_name = tf.saved_model.DEFAULT_SERVING_SIGNATURE_DEF_KEY
request.inputs["sequences"].CopyFrom(tp_data)
return request
# Read the data
df = pd.read_csv("serving_sample.csv", skipinitialspace=True)
# Extract and pre-process sensor data
data = df[["ch0", "ch1", "ch2", "ch3", "ch4", "ch5"]].values.astype(np.float32)
# Build a batch of samples
sample_batch = np.zeros((args.batch_size, args.sample_length, data.shape[-1]), dtype=np.float32)
for i in range(args.batch_size):
sample_batch[i, :, :] = data[i : i + args.sample_length, :]
# Build a prediction request
request = predict_pb2.PredictRequest()
request.model_spec.name = "classifier"
request.model_spec.signature_name = tf.saved_model.DEFAULT_SERVING_SIGNATURE_DEF_KEY
request.inputs["sequences"].CopyFrom(make_tensor_proto(sample_batch, dtype=tf.float32))
# Predict
channel = grpc.insecure_channel("0.0.0.0:8500")
stub = prediction_service_pb2_grpc.PredictionServiceStub(channel)
result = stub.Predict(request, 60.0) # 60 secs timeout
print(result)
Comments